Table of Contents
@__START-HERE__@ CEPH Course overview
CEPH pre concepts
What is an Object Storage??
Copy/paste
From Wikipedia, the free encyclopedia
Object storage (also known as object-based storage) is a computer data storage architecture that manages data as objects, as opposed to other storage architectures like file systems which manages data as a file hierarchy, and block storage which manages data as blocks within sectors and tracks. Each object typically includes the data itself, a variable amount of metadata, and a globally unique identifier. Object storage can be implemented at multiple levels, including the device level (object-storage device), the system level, and the interface level. In each case, object storage seeks to enable capabilities not addressed by other storage architectures, like interfaces that can be directly programmable by the application, a namespace that can span multiple instances of physical hardware, and data-management functions like data replication and data distribution at object-level granularity.
Object storage systems allow retention of massive amounts of unstructured data. Object storage is used for purposes such as storing photos on Facebook, songs on Spotify, or files in online collaboration services, such as Dropbox.
blablabla, summary:
- An Object Storage (like our ceph) is a set of services (and usually, servers) which provides a easy way to store tons of objects.
- You don't have to mind about how/where to place them in one “filesystem”.
What is an Object
An object can be defined as a static element, for example:
- photo
- video
- js/javascript
- css
- pdf
- TID

What will not be a object? A dynamic element:
- asp
- php
- cgi
- json (usually the information inside a json is dynamic)
- xml (same as previous case)
Why do we need an Object Storage
- Will be a cost-effective way to store tons of data (see “What is an object” and think about it)
- Will scale forever, in the case we run out of space, is compatible with Amazon S3, Google Objects and maybe any other manufacturer which provides Object Storage services/appliances.
- Have you think about TID's, we can have them out of oracle!
CEPH: course overview
CEPH: Architecture Overview
| Documentation | |
|---|---|
| Name: | CEPH: Architecture Overview |
| Description: | This document is the start line to understand this technology |
| Modification date : | 11/02/2019 |
| Owner: | dodger |
| Notify changes to: | dodger |
| Tags: | ceph, oss |
| Scalate to: | The_fucking_bofh |
Initial concepts
What is:
- Ceph is a advanced Object Storage Service (OSS).
- A easy way to store tons of objects of any kind and store it in multiple ways: S3/Swift, NFS, Block device.
- It's fast, scale-out and fault tolerance.
What is NOT:
- A database
- A cache
You can read/watch a basic introduction here: https://ceph.com/ceph-storage/
Basic architecture
VERY BASIC (2 minutes approach)
From a very simple point of view: Ceph acts as a disk.
With the correct OS library like can be the kernel module for “ext4”/“btrfs”, you'll be able to read/write directly.
This library is called librados.
And interact with RADOS the reliable autonomic distributed object store which is the Object storage itselv.
Continuing with this simple view, like ext4 for example, you'll have data blocks and journal blocks to maintain consistency; that are OSD (object store data) and MON (monitoring) nodes:
- OSD: serve data
- MON: keep track of OSD nodes, DOES NOT SERVE DATA
So you'll have something like this:
BASIC Architecture
Going deeper, you'll find that the data placement over OSD nodes is calculated by an algorithm called CRUSH: Controlled Replication Under Scalable Hashing which is:
- Pseudo-random, very fast, repeatable and deterministic
- Makes a uniform data distribution
- Results in a stable mapping of data (with very limited data migration on changes)
- It has a rule-based configuration: adjustable replication, weights …
So when a client want to write data in the CEPH cluster though RADOS, librados in the client side invokes CRUSH to perform the calculation on where of the available OSD's write the data.
That result in a very strong architecture with no single point of failure, cause you'll not have a/many node/s taking care of metadata.
Its also really fast: you'll have n*osd servers to perform read/writes.
Its robust, if any of the OSD node fails, the data is replicated N times (where N is a config option) through other OSD's and will be accessible with the CRUSH calculation.
Also if any OSD fail, the MONitors will re-map the cluster and OSD's will re-replicate the data to have copied N times in the cluster.
In a graph
Usage Cases
CEPH as REST Object Storage
The unique diference in this case is there's a new component involved, the gateway which translate HTTP/REST into librados.
That's all.
You'll have a lot of overhead/performance gap using the gateway instead of using librados directly…
So if you take the previous graph, simplified, you'll have:
CEPH as Filesystem Architecture
Official documentation: https://docs.ceph.com/docs/master/cephfs/
Again, the diference in using CEPH as “filesystem” is that there's another component: the “Metadata server”.
Metadata a role similar to Monitor:
- it DOES NOT SERVE DATA
- It has the metadata database, that is a “inode” in a common filesystem.
- The Metadata nodes also replicate and vote between them.
- The filesystem tree is split dynamically between all the metadata nodes.
Real Life
ePayments PRO/PRE
Node list:
- Admin:
- ACCLM-OSADM-001
- OSD:
- ACCLM-OSD-001
- ACCLM-OSD-002
- ACCLM-OSD-003
- ACCLM-OSD-004
- ACCLM-OSD-005
- Gateways:
- ACCLM-OSGW-001
- ACCLM-OSGW-002
- Monitors:
- ACCLM-OSM-001
- ACCLM-OSADM-001
Clover schematics (here comes the monster)
HAproxies:
- AVMLP-OSLB-001
- AVMLP-OSLB-002
Object Gateways:
- AVMLP-OSGW-001
- AVMLP-OSGW-002
- AVMLP-OSGW-003
- AVMLP-OSGW-004
Monitors:
- AVMLP-OSM-001
- AVMLP-OSM-002
- AVMLP-OSM-003
- AVMLP-OSM-004
- AVMLP-OSM-005
- AVMLP-OSM-006
Metadata servers:
- AVMLP-OSFS-001
- AVMLP-OSFS-002
- AVMLP-OSFS-003
- AVMLP-OSFS-004
Data servers:
- AVMLP-OSD-001
- AVMLP-OSD-002
- AVMLP-OSD-003
- AVMLP-OSD-004
- AVMLP-OSD-005
- AVMLP-OSD-006
- AVMLP-OSD-007
- AVMLP-OSD-008
- AVMLP-OSD-009
- AVMLP-OSD-010
- AVMLP-OSD-011
- AVMLP-OSD-012
- AVMLP-OSD-013
- AVMLP-OSD-014
- AVMLP-OSD-015
- AVMLP-OSD-016
- AVMLP-OSD-017
- AVMLP-OSD-018
- AVMLP-OSD-019
- AVMLP-OSD-020
Clover

As object gateway
As Filesystem (cephfs)
Public ceph schema
Considerations for newcomers
When requesting access to any of our object storages or if you're a newcomer, you should know that:
- The_fucking_bofh team will give you the “access_key” and “secret_key” to access the object storage, but also will inform you of the name of the user, this username is unique and will be something related to the name of the project.
- The_fucking_bofh team will not create the bucket, you can easily do it
- bucket names are unique across ONE object storage instance: If you create the bucket “test” no one can create another bucket named “test” in the same object storage. Have this in mind as you're sharing ceph with other users and with yourself (for PRO/PRE/DEV/TEST/STAGING/DEMO/SERVERLESS)! So don't use “ciberterminal” as bucketname
- What you'll need to connect to the object storage is:
- Endpoint url: for example https://clover.ciberterminal.net
- access_key
- secre_key
- knowledge of how to connect.
- Please specify where do you want your user to be created, for example: PRO/PRE/DEV/TEST/STAGING/DEMO/SERVERLESS
Here you have a template to request a new user for the object storage:
Good morning #infrastructure, We're facing a new project that involves store tons of objects and We want to use our incredible Ceph installation. Please provide us a new User so we can store all the data from this project. Name of the project: "This_template_sucks" Environment: DEVELOPMENT Expected number of buckets: 666 Thanks for your effort, best regards!
Appendix 1 : GUI's and clis (s3browser/rclone)
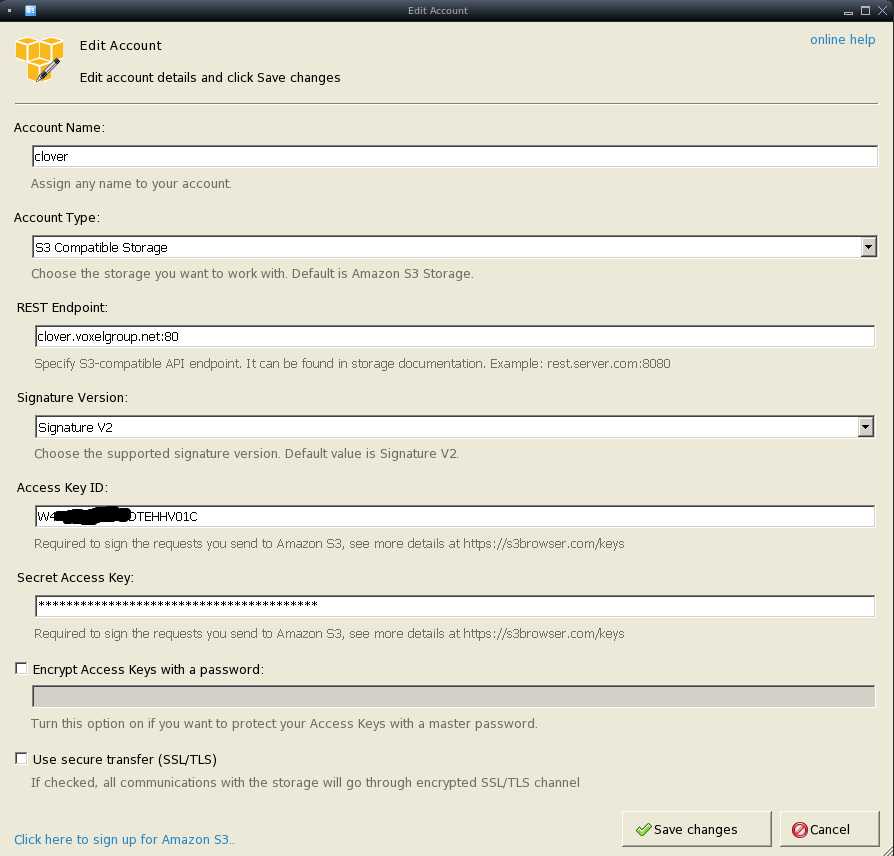
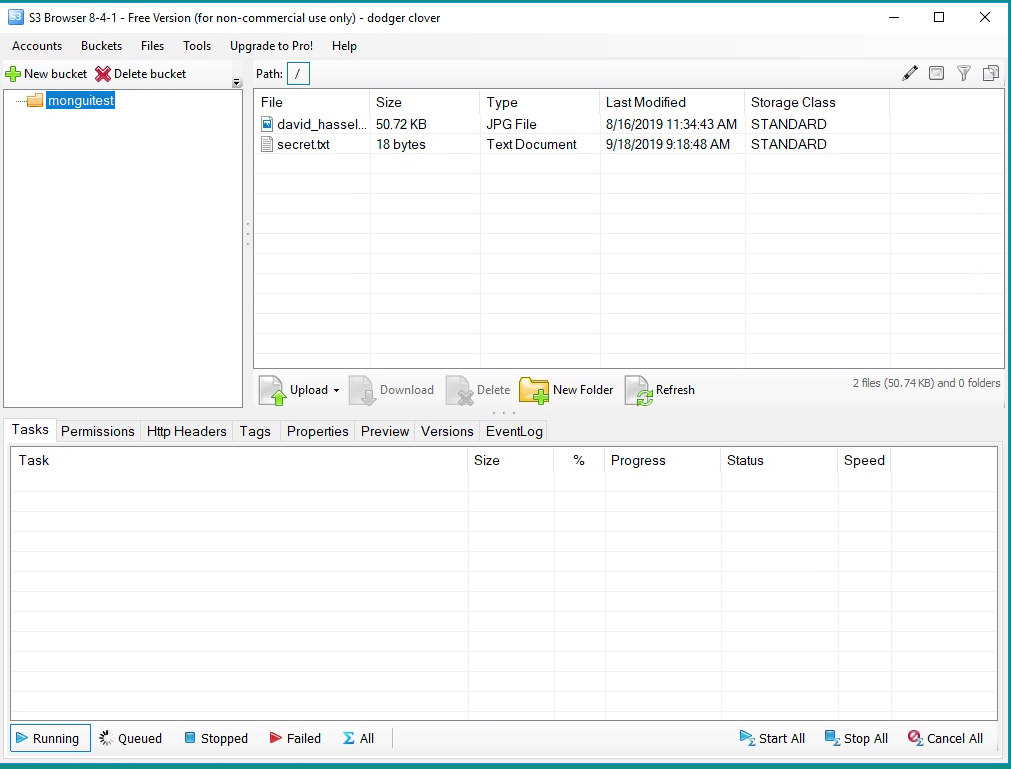
s3browser
Rclone: rsync for object storage
Appendix 2 : Use Amazon S3 naming method
Amazon Naming method consist on:
Appendix 3 : Using ACL's
Appendix 4 : Bonus thoughts
Using ACL's we can publish the object storage to internet (like amazon's S3) to avoid re-using IIS/dotnet/netcore apps only to serve files.